| VIEWING FREQUENCY
| LOW MED HIGH
|-----------------------------
|
MALE | 8 3 16
|
FEMALE | 9 8 6
|
Note the correct format for reporting x2: The 2 indicates the degrees of freedom, N (50 in this case) equals the total number of subjects, 6.60 is the actual value of x2 and .04 is the probability value, representing the odds of the results being due to pure chance.
MEAN SD N
MALE 3.97222 2.92891 27
FEMALE 2.39130 1.41386 23
Or if we made no prediction about the outcome:
Note the correct format for reporting t: The 48 indicates the degrees of freedom, 2.36 is the actual value of t and .02 is the probability value, representing the odds of the results being due to pure chance.
Even though the t-test gives us a higher level of significance, both because it is a more powerful parametric test and because we analyzed all the variance rather than discarding some by grouping the actual viewing frequency values, it fails to show us that low frequency television viewers are just about equally split between men and women.
This was a very small sample. With a larger sample the Chi Square probability could easily equal the results from the t-test and give us a better picture of the variance pattern.
Note that the actual values for t and x2 are virtually meaningless to anyone but a statistician. While we need to follow the standard format for reporting each statistic, it is the probability value alone which will be meaningful to most readers.
For years there have been statistics that have attempted to measure the size or magnitude of a relationship to help expand our understanding of our data beyond just significance. These statistics have, however, been difficult to interpret and have not been widely accepted. In 1988 Jacob Cohen published Statistical Power Analysis for the Behavioral Sciences which, along with examining the whole issue of magnitude in depth, proposed a new statistic which has come to be called Cohen's d.
This statistic is now considered THE appropriate measure of effect size (magnitude) to accompany the independent t test. While not every statistician agrees, Cohen provided ranges for d corresponding to small, medium, and large effect sizes. They are:
Computing d can be a bit intimidating, but a statistician named Lee Becker has developed a calculator and kindly placed it on the Web for all to use. You simply place the means and standard deviations for the 2 groups in the appropriate boxes and click on "Compute." The calculator spits out Cohen's d and r which is more difficult to interpret..00 - .20 Small Effect Size .21 - .50 Medium Effect Size > .50 Large Effect Size
The calculation for the independent t test above is shown in the graphic below.
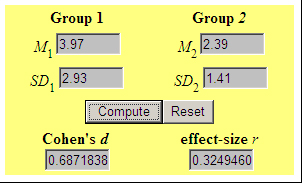
Note that the Cohen's d rounds to .69 which is considered a large effect size. The relationship would be written as follows in the body of the paper:
The relationship between gender and viewing frequency could therefore be called "highly significant" and "large" when discussing the findings.
Note that Cohen's d is NOT an accurate measure of magnitude when applied to a t test for related means.
There are a variety of statistics associated with each measure of significance which are coming to be accepted as appropriate corresponding measures of effect size (magnitude). At present Cohen's d has the most widely accepted scale for interpreting the results. It is also popular because the independent t test is so widely used in many types of research.
While not as accepted as Cohen's d, there is a similar statistic known as eta squared (η2) which is used to measure effect size with ANOVA, which is used to measure significance when your independent variable has more than 2 values.
There are reasonably well accepted values for interpreting η2. They are:
.01 - .05 Small Effect Size .06 - .13 Medium Effect Size > .13 Large Effect Size
In the table below is displayed the descriptive values of data comparing viewing frequency with type of program.
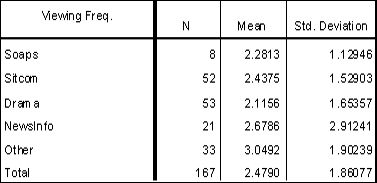
Some versions of SPSS calculate eta squared (η2) for you, but it can be computed using a simple calculator to perform the following equation:
The SPSS printout for the ANOVA (F test) described above is shown in the following table:
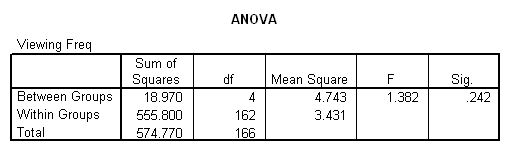
Using the formula above, η2 = .03. The relationship would be written as follows (if at all) in the body of the paper:
So in your results you would report that viewing frequency and program type were not found to be significantly related. In most cases you would stop there, not including any statistics. If there HAD been a significant relationship, you would have then described it as "small."
While harder to interpret than Cohen's d, Cramer's V is considered the best statistic to measure the effect size (magnitude) when dealing with nominal data using Chi Square as your measurement for significance. SPSS will generate Cramer's V as one of the options under crosstabulation, so calculation is not an issue.
A very "crude" interpretation of V that is generally accepted is as follows:
Cramer's V for the Crosstabulation example above equals .36. The relationship would be written as follows in the body of the paper:<.06 Negligible Relationship .06 - .10 Weak Relationship .11 - .15 Moderate Relationship .15 - .25 Strong Relationship > .25 Very Strong Relationship
The relationship between gender and viewing frequency could therefore by called "significant" and "very strongly related."
Note that while the t test yielded a higher significance level (p = .01, "highly significant"), both Cohen's d and Cramer's V indicate a high magnitude for the relationship between gender and viewing frequency.

Return to TVR 400 Home Page